I recently started working with Kubernetes Descheduler. Here, we’ll explore how to use it to balance pods and services running on Kubernetes in real world scenarios.
Production use cases
Kubernetes offers a range of built-in resources enabling effective control over node decisions. It’s worth noting the requiredDuringSchedulingIgnoredDuringExecution field, impacting decisions only during Scheduler and not affecting rules post-Pod deployment on the node. Similarly, concepts like Taint/Toleration remain unaffected after deployment.
While such an approach is generally suitable, there are scenarios where Pod reallocation becomes necessary. For instance, adding a new node might lead to uneven resource distribution, causing a need for Pod relocation. Additionally, changes in node Labels don’t impact running Pods, necessitating adjustments based on the latest Labels.
In typical cases, rescheduling can be initiated by actively updating or redeploying applications. Alternatively, tools like Descheduler provide an automated mechanism for dynamic rescheduling during runtime.
Installation
Descheduler offers various deployment options, including Job, CronJob, and Deployment. The Deployment approach incorporates a High Availability (HA) architecture using the Leader Election mechanism. This architectural design primarily operates in an AP mode, ensuring the execution of only one descheduling decision simultaneously.
Furthermore, the server includes Metrics that Prometheus can collect and analyze for future debugging purposes.
In the subsequent illustration, Helm is utilized to facilitate the deployment, installation, and activation of the HA mechanism.
$ helm repo add descheduler https://kubernetes-sigs.github.io/descheduler/
Prepare the following values.yaml
replicas: 3
leaderElection:
enabled: true
kind: Deployment
Install via Helm
$ helm upgrade --install descheduler --namespace kube-system descheduler/descheduler --version=0.28.0 -f values.yaml
Upon the successful installation, inspect the system details. It becomes apparent that three replicas are present, and discerning from the lease data, it is evident that the Pod labeled as “blf4l” has emerged victorious in the election.
$ kubectl -n kube-system get lease
NAME HOLDER AGE
descheduler descheduler-845867b84b-blf4l_f48c09d6-2633-4ec5-95aa-d0b62ffe412c 5m9s
$ kubectl -n kube-system get pods -l "app.kubernetes.io/instance"="descheduler"
NAME READY STATUS RESTARTS AGE
descheduler-845867b84b-7kv9z 1/1 Running 0 2m15s
descheduler-845867b84b-blf4l 1/1 Running 0 2m15s
descheduler-845867b84b-d4tw7 1/1 Running 0 2m15s
How does the Descheduler arch. look like ?
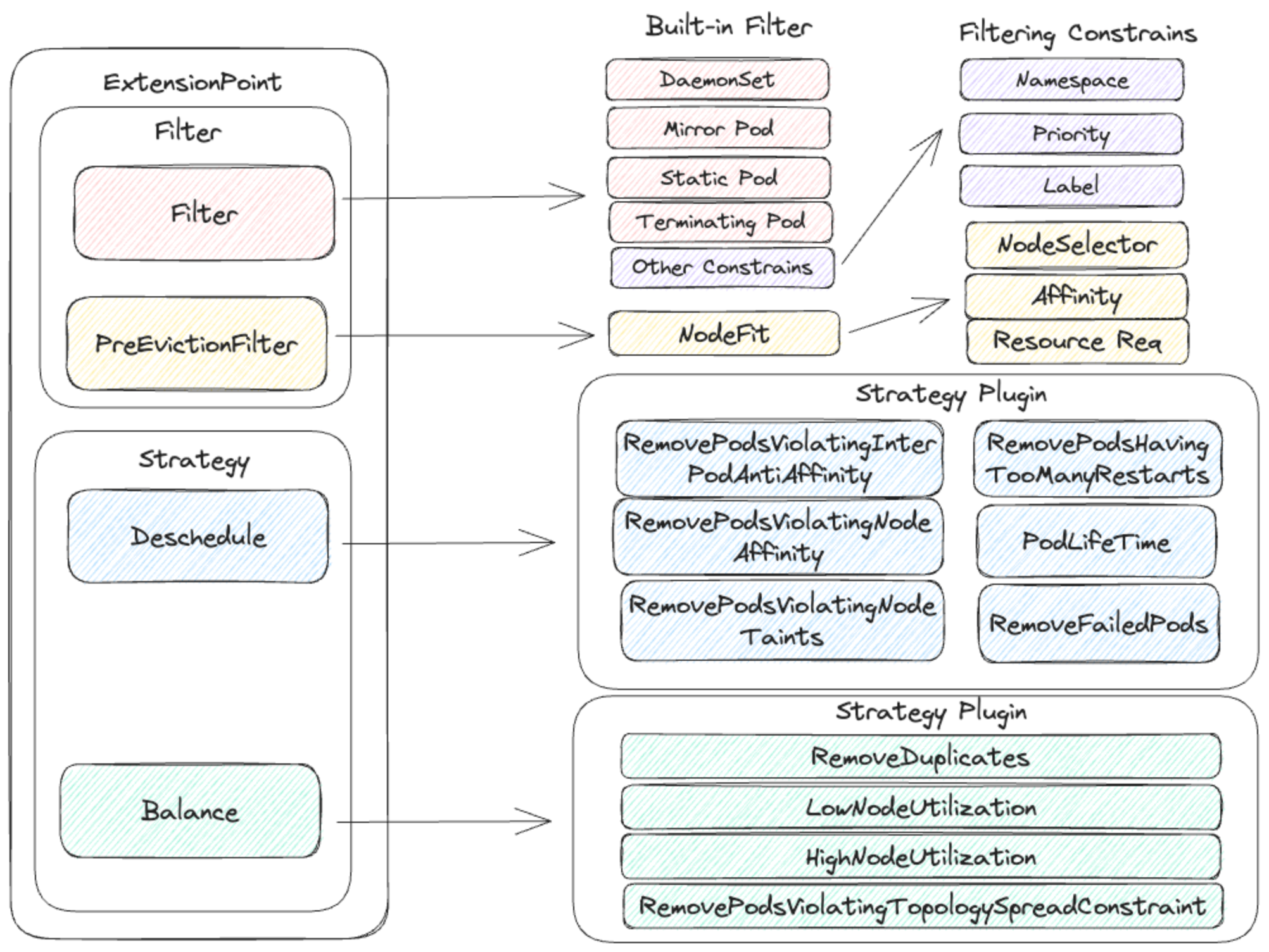
The Descheduler architecture revolves around the configuration of policies, with policies being comprised of two essential components: Evictor and Strategy.
The role of the Strategy is to determine the conditions under which Pods should undergo reallocation, while the Evictor is responsible for identifying Pods that are eligible for reallocation.
Evictor
Within the Evictor, there are two built-in mechanisms: Filter and PreEvicitionFilter.
The Filter is instrumental in specifying criteria that exempt certain Pods from the “rescheduling” process. Examples of such exemptions include:
- Static Pods
- DaemonSets
- Pods in the process of termination
- Pods meeting specific conditions such as Namespace, Priority, or Label criteria.
To delve deeper into the specifics of these rules, one can examine the code. It’s noteworthy that some rules are hardcoded, while others are configured through constraints.
func (d *DefaultEvictor) Filter(pod *v1.Pod) bool {
checkErrs := []error{}
if HaveEvictAnnotation(pod) {
return true
}
ownerRefList := podutil.OwnerRef(pod)
if utils.IsDaemonsetPod(ownerRefList) {
checkErrs = append(checkErrs, fmt.Errorf("pod is a DaemonSet pod"))
}
if utils.IsMirrorPod(pod) {
checkErrs = append(checkErrs, fmt.Errorf("pod is a mirror pod"))
}
if utils.IsStaticPod(pod) {
checkErrs = append(checkErrs, fmt.Errorf("pod is a static pod"))
}
if utils.IsPodTerminating(pod) {
checkErrs = append(checkErrs, fmt.Errorf("pod is terminating"))
}
for _, c := range d.constraints {
if err := c(pod); err != nil {
checkErrs = append(checkErrs, err)
}
}
if len(checkErrs) > 0 {
klog.V(4).InfoS("Pod fails the following checks", "pod", klog.KObj(pod), "checks", errors.NewAggregate(checkErrs).Error())
return false
}
return true
}
The PreEvicitionFilter presently incorporates the “NodeFit” mechanism. Before selecting a Pod for eviction, it assesses whether the Pod is eligible for eviction based on the availability of nodes that satisfy its own NodeSelector, Affinity, Taint, or Resource Request for redeployment.
For the detailed operational logic, one can examine the program code below. If the user configures “NodeFit=true,” the main function is triggered to scrutinize whether there exists a node, given the current conditions, that can facilitate the redeployment of the specified Pod.
func (d *DefaultEvictor) PreEvictionFilter(pod *v1.Pod) bool {
defaultEvictorArgs := d.args.(*DefaultEvictorArgs)
if defaultEvictorArgs.NodeFit {
nodes, err := nodeutil.ReadyNodes(context.TODO(), d.handle.ClientSet(), d.handle.SharedInformerFactory().Core().V1().Nodes().Lister(), defaultEvictorArgs.NodeSelector)
if err != nil {
klog.ErrorS(err, "unable to list ready nodes", "pod", klog.KObj(pod))
return false
}
if !nodeutil.PodFitsAnyOtherNode(d.handle.GetPodsAssignedToNodeFunc(), pod, nodes) {
klog.InfoS("pod does not fit on any other node because of nodeSelector(s), Taint(s), or nodes marked as unschedulable", "pod", klog.KObj(pod))
return false
}
return true
}
return true
}
Strategy
The framework of the Strategy primarily comprises the Strategy itself, which encompasses various Strategy Plugins. These plugins form integral components of the overarching algorithm, responsible for determining when it is appropriate to initiate the rescheduling of a Pod. These Strategy Plugins are categorized under the same Strategy based on their shared objectives. Presently, the system includes two default built-in Strategies, namely Deschedule and Balance.
The roster of built-in Strategy Plugins stands at approximately 10. For more comprehensive insights, you can consult the official documentation.
- RemoveDuplicates
- RemovePodsViolatingNodeAffinity
- RemovePodsHavingTooManyRestarts
- HighNodeUtilization
- … etc
Descheduling primarily focuses on the reallocation of Pods triggered by conditions such as Label, Taint, and Affinity, whereas the Balance Strategy aims to redistribute Pods based on factors like node utilization and Pod distribution.
The diagram below endeavors to categorize the aforementioned rules, outlining the specific rules and associated Strategy Plugins for each distinct Filter/Strategy.
A working example
To configure Descheduler settings, adjustments can be made in the relevant configmap. When utilizing Helm for installation, any modifications can be overwritten by the values file.
It’s crucial to note the distinct setting methods for apiVersion. Helm currently employs descheduler/v1alpha2. The examples provided in official documentation align with descheduler/v1alpha2. Therefore, exercising caution to avoid mixing different versions is essential.
To enable the RemovePodsHavingTooManyRestarts Strategy Plugin and set the threshold to 5, modify the values.yaml file as follows. Upon redeployment, these changes will take effect:
strategy:
removePodsHavingTooManyRestarts:
enabled: true
restartThreshold: 5
Ensure that these modifications align with the specified version (descheduler/v1alpha2) for seamless integration.
replicas: 3
leaderElection:
enabled: true
kind: Deployment
deschedulerPolicyAPIVersion: "descheduler/v1alpha2"
deschedulerPolicy:
profiles:
- name: test
pluginConfig:
- name: "RemovePodsHavingTooManyRestarts"
args:
podRestartThreshold: 5
includingInitContainers: true
plugins:
deschedule:
enabled:
- "RemovePodsHavingTooManyRestarts"
Next, deploy an unstable Pod and observe what happens when the Pod is restarted five times.
apiVersion: apps/v1
kind: Deployment
metadata:
name: www-deployment
spec:
replicas: 1
selector:
matchLabels:
app: www
template:
metadata:
labels:
app: www
spec:
containers:
- name: www-server
image: hwchiu/python-example
command: ['sh', '-c', 'date && no']
ports:
- containerPort: 5000
protocol: "TCP"
It can be observed from the following logs that when the Pod is restarted more than 5 times, that is, after the sixth time, the Pod is removed and the new Pod is deployed smoothly.
$ kubectl get pods -w
NAME READY STATUS RESTARTS AGE
www-deployment-77d6574796-bhktm 0/1 CrashLoopBackOff 4 (53s ago) 2m37s
www-deployment-77d6574796-bhktm 0/1 Error 5 (92s ago) 3m16s
www-deployment-77d6574796-bhktm 0/1 CrashLoopBackOff 5 (12s ago) 3m28s
www-deployment-77d6574796-bhktm 0/1 CrashLoopBackOff 5 (104s ago) 5m
www-deployment-77d6574796-bhktm 0/1 Terminating 5 (104s ago) 5m
www-deployment-77d6574796-rfkws 0/1 Pending 0 0s
www-deployment-77d6574796-bhktm 0/1 Terminating 5 5m
www-deployment-77d6574796-rfkws 0/1 Pending 0 0s
www-deployment-77d6574796-rfkws 0/1 ContainerCreating 0 0s
www-deployment-77d6574796-bhktm 0/1 Terminating 5 5m
www-deployment-77d6574796-bhktm 0/1 Terminating 5 5m
www-deployment-77d6574796-bhktm 0/1 Terminating 5 5m
www-deployment-77d6574796-bhktm 0/1 Terminating 5 5m
At the same time, you can observe from the descheduler that the following logs clearly indicate which node the Pod was removed for and for what reason.
I1112 13:08:25.209203 1 descheduler.go:156] Building a pod evictor
I1112 13:08:25.209408 1 toomanyrestarts.go:110] "Processing node" node="kind-control-plane"
I1112 13:08:25.209605 1 toomanyrestarts.go:110] "Processing node" node="kind-worker"
I1112 13:08:25.209648 1 toomanyrestarts.go:110] "Processing node" node="kind-worker2"
I1112 13:08:25.209687 1 toomanyrestarts.go:110] "Processing node" node="kind-worker3"
I1112 13:08:25.209735 1 toomanyrestarts.go:110] "Processing node" node="kind-worker4"
I1112 13:08:25.261639 1 evictions.go:171] "Evicted pod" pod="default/www-deployment-77d6574796-bhktm" reason="" strategy="RemovePodsHavingTooManyRestarts" node="kind-worker4"
I1112 13:08:25.261811 1 profile.go:323] "Total number of pods evicted" extension point="Deschedule" evictedPods=1
I1112 13:08:25.261856 1 descheduler.go:170] "Number of evicted pods" totalEvicted=1
Official documents also provide various usages of different Strategy Plugins, so I won’t go into repeated demonstrations here.
Summary
Descheduler comes equipped with an intrinsic mechanism for the dynamic redeployment of Pods. Certain strategies revolve around deployment conditions, encompassing factors like Label, Taint, and Affinity. Conversely, other strategies are tailored to adapt based on node usage.
This later strategy facilitates the dispersal of Pods contingent on node utilization metrics, be it quantity or leveraging the Cluster Autoscaler to retire underutilized nodes, thereby optimizing cost-efficiency.